CareerVault
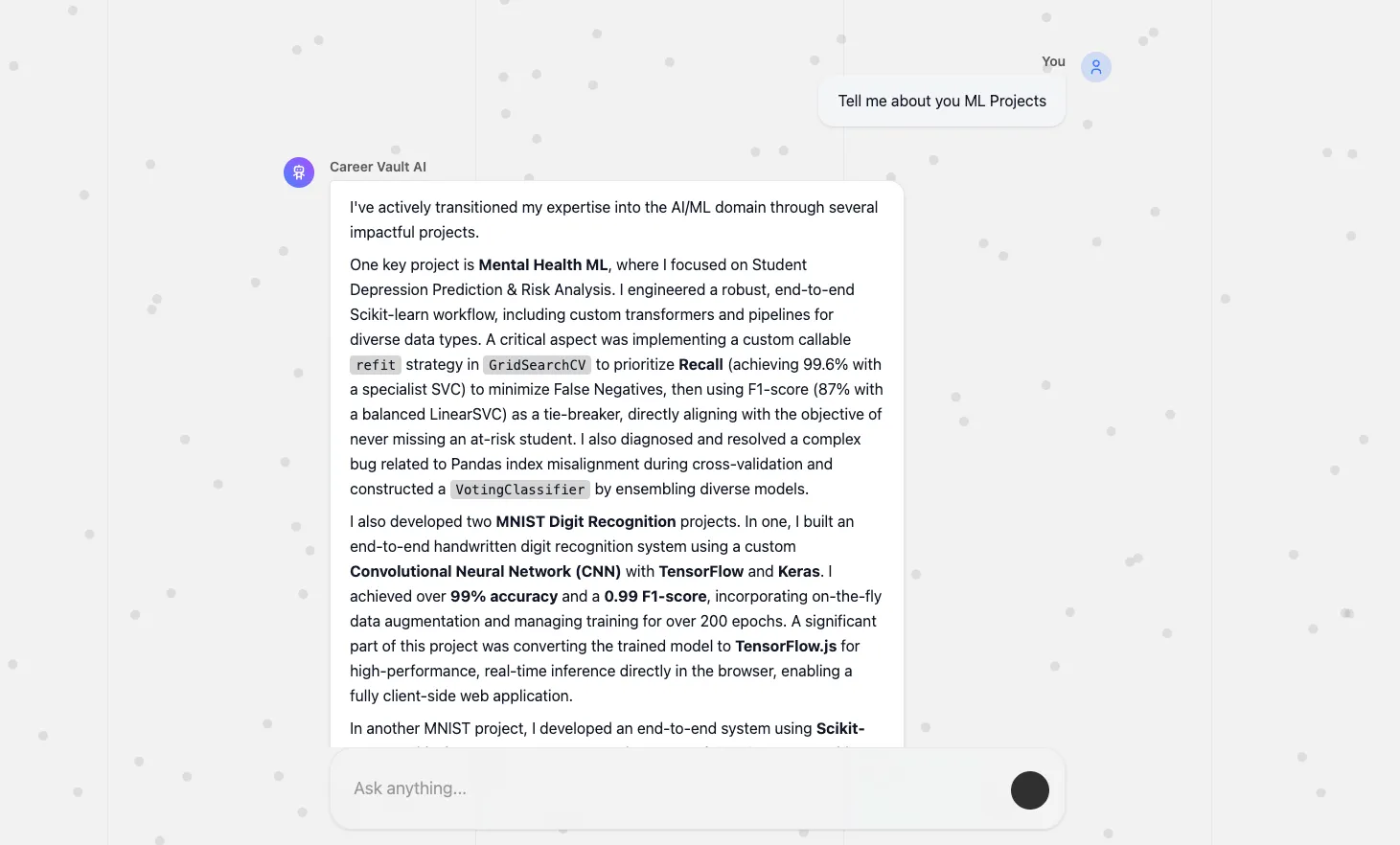
Chat UI - Second Question: Maintaining deep conversational context across multiple turns using LlamaIndex's CondensePlusContextChatEngine.

CareerVault: An Interactive RAG Portfolio with Persistent Memory
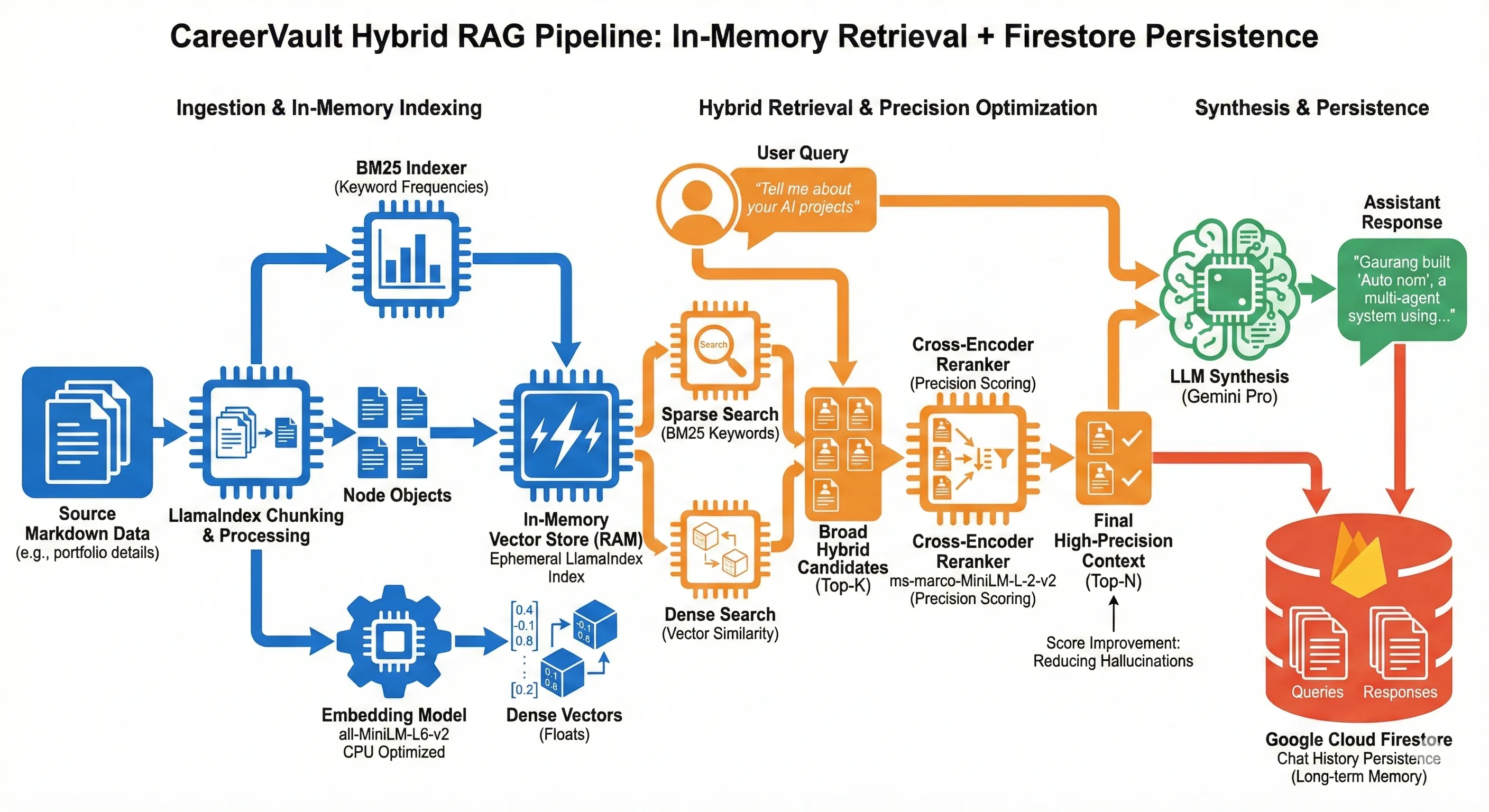
Hybrid Retrieval Pipeline: Combining Vector Search (MiniLM-L6) with Cross-Encoder Reranking (MS-Marco) for high-precision context injection.
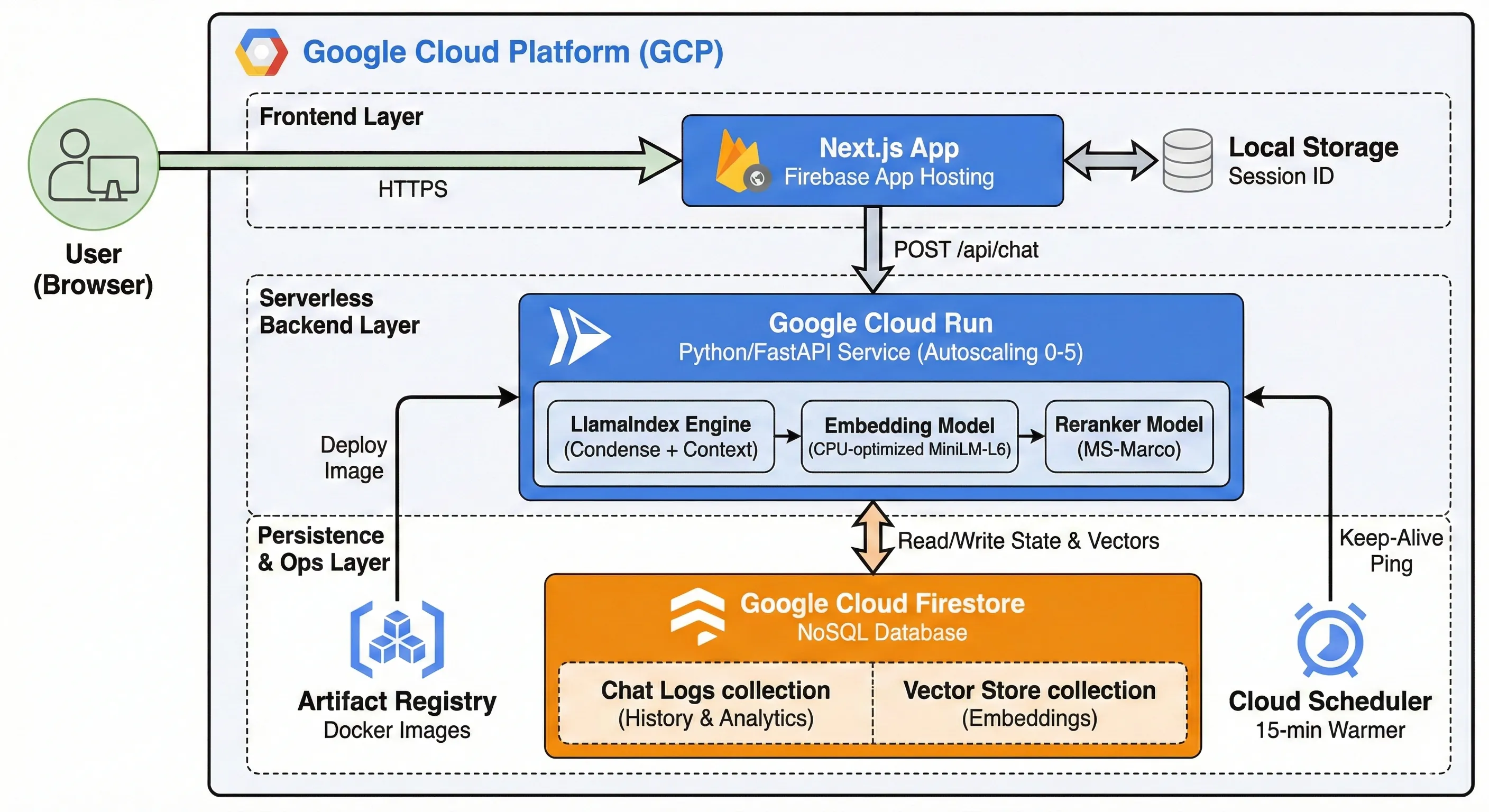
Serverless Architecture: Deployed on Google Cloud Run with Firestore for persistent, server-side chat history storage.
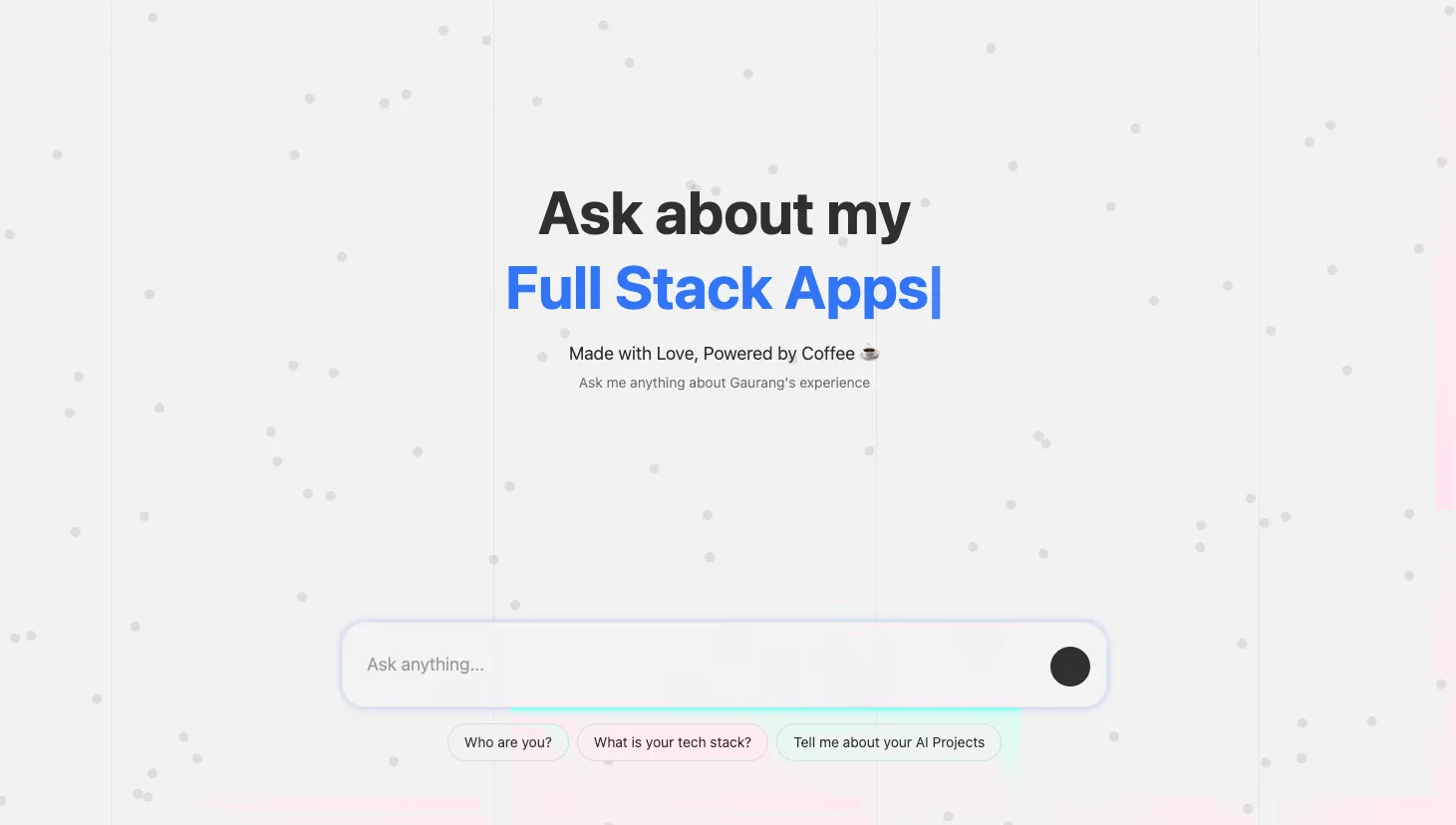
Chat UI - Default Screen: A polished,interface built with Next.js and Tailwind CSS.
Chat UI - First Question: Engaging the user with suggested query chips to reduce cognitive load.
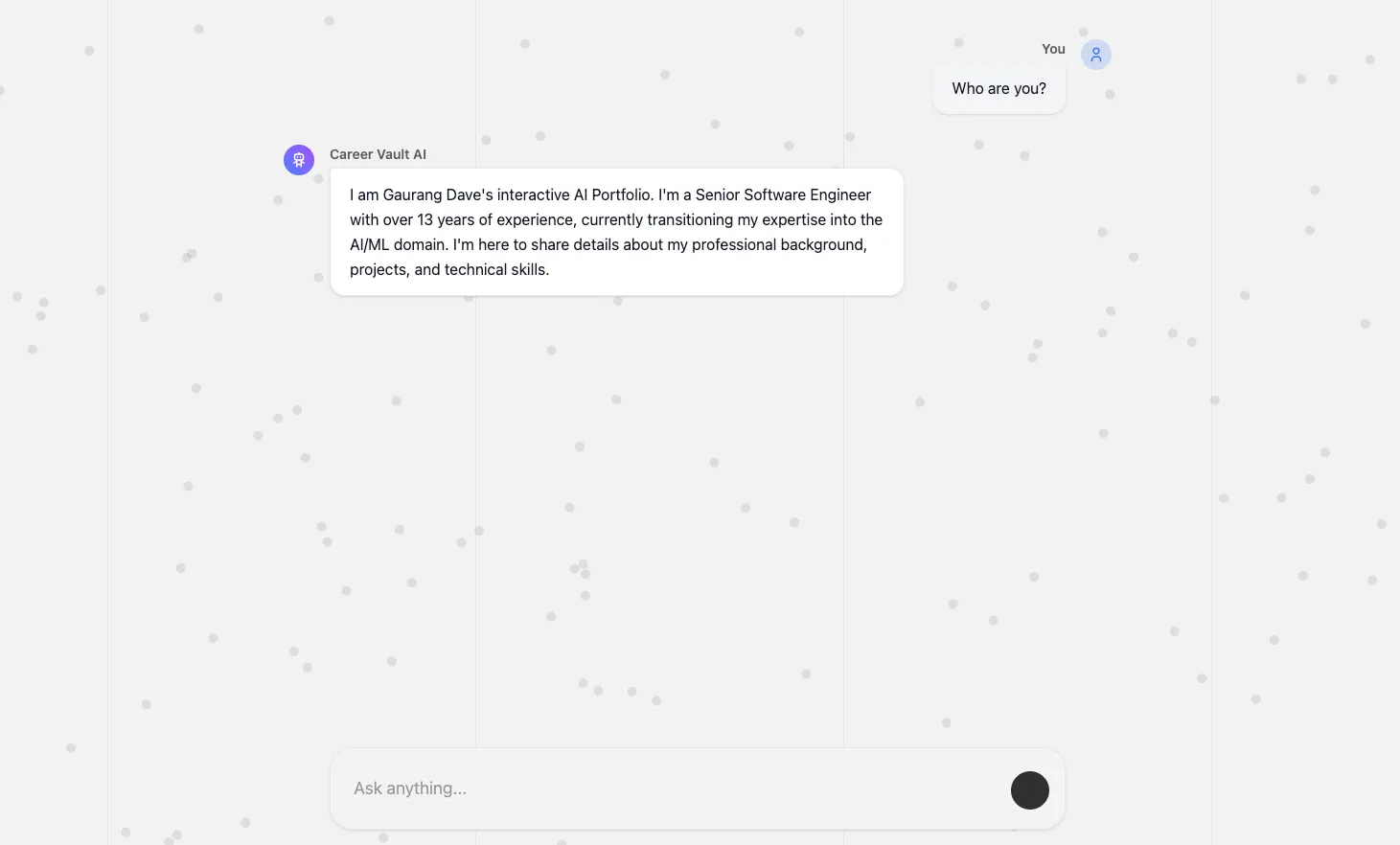
Chat UI - Second Question: Maintaining deep conversational context across multiple turns using LlamaIndex's CondensePlusContextChatEngine.
CareerVault: An Interactive RAG Portfolio with Persistent Memory
Project Description
A production-ready RAG application that serves as an intelligent 'Digital Twin,' answering queries about my professional history using a hybrid retrieval pipeline and serverless state management.
Responsibilities
- Architected a serverless RAG pipeline on Google Cloud Run, utilizing LlamaIndex's 'CondensePlusContextChatEngine' to maintain deep conversational context across multiple turns.
- Engineered a robust state management system using Firestore to persist chat history server-side, enabling both long-term memory for the user and offline quality analysis for the developer.
- Optimized Docker container sizing by over 70% (from 5.5GB to ~1.5GB) by enforcing CPU-only PyTorch wheels and implementing a multi-stage build process that excludes heavy CUDA GPU drivers.
- Solved the 'Serverless Cold Start' problem (typically 40s+ for LLM apps) by deploying a Cloud Scheduler 'Warmer Bot' that pings the service every 15 minutes, ensuring sub-second response times.
- Implemented a two-stage retrieval strategy: broad semantic search using 'all-MiniLM-L6-v2' followed by a precision pass using the 'ms-marco-MiniLM-L-2-v2' Cross-Encoder to minimize hallucination.
- Built a polished, terminal-themed UI using Next.js and Tailwind CSS, featuring a custom 'useSession' hook that generates and persists UUIDs client-side to maintain chat history across page reloads.
- Configured a production-grade 'autoscaling.knative.dev' strategy with a max-instance limit of 5, balancing high availability with strict cost controls.
- Integrated a 'Typewriter' effect and 'Suggested Query Chips' to guide user interaction and reduce the cognitive load of the 'Blank Page Problem' common in chatbot interfaces.
Related Links
Technology
DockerFastAPIFirestoreLlamaIndexNext.jsPython